Breaking Barriers and Achieving Cutting Edge with LLM-T-B: Developing code and a comprehensive concept to build a Telegram BOT that can be used across all businesses for various tasks
We are revolutionizing traditional call centers and customer relations by harnessing unprecedented artificial intelligence, especially LLMs.

Note: Before starting this article, it is important to state that the goal of presenting and developing this idea is not to eliminate Call Center jobs or any other jobs that could be affected by it. The sole purpose of this idea is to enhance productivity using new AI tools. This will improve the working conditions for employees in Call Centers or any other jobs that utilize LLM-T-B and will lead to greater customer satisfaction.
“I ask all those who read this article and all developers and AI enthusiasts, if you are interested in working on and developing LLM-T-B, to connect with me on Medium or LinkedIn so that we can develop a product that will change the game soon. The complete code for LLM-T-B, as discussed in this article, will soon be published on my GitHub.”
Introduction
One of the most crucial and significant departments in both large and small organizations is the Call Center. A Call Center is akin to the emergency room of a hospital, serving as the frontline in customer communication with companies. The comparison to an emergency room stems from the fact that most Call Centers, like emergency rooms, operate 24/7. Additionally, they are often the first point of contact for identifying problems, making them inherently stressful environments.
Often, Call Centers are undervalued. The typical mental image of a Call Center employee is someone with a headset, sitting at their desk, sipping tea or another beverage, while easily handling customer inquiries with a single button press on their all-access system. However, this is far from the reality. The most critical aspect of Call Centers is speed and time management.
The primary task that enhances the speed of response and reduces the duration of conversations, whether through chat or voice calls, is quick and accurate access to information that resolves the issue. Moreover, the number of personnel, especially in large company Call Centers, is usually high. Managing onsite and remote employees (since Call Centers are one of the jobs that can be performed remotely), particularly in quickly finding solutions to problems, can be the greatest advantage for a Call Center.
In this article, we aim to develop a system that, with the help of AI and specifically LLMs, can increase speed and reduce the response time leading to problem resolution. We intend to develop a product using LLMs and a Telegram BOT, which I will refer to as LLM-T-B. This BOT will create a reference system for the company that can also encompass other departments, meaning it will not be exclusive to the Call Center. Additionally, it will enable direct interaction with customers. Join me on this journey!
The First Task of the Telegram BOT!
The initial task for this LLM-T-B is to monitor the real-time status of the Call Center and manage employee breaks during their shifts. It's important to note that the following suggestions are optional and may differ between companies. Call Centers typically operate 24/7, so we will establish three shifts for LLM-T-B and specify the staff present during each shift. Additionally, we will create a feature that allows an employee to be added to a different shift if they plan to work overtime or need to switch shifts for any reason. The rules established for this can be adaptable and may change based on real-time conditions.
What does this mean? Every company has a system for handling calls. We want to integrate LLM-T-B with this system using an API and establish guidelines so that LLM-T-B can independently determine appropriate break times for employees based on the volume of incoming calls. The permissible break durations can vary based on the company’s policies, for example, “n” minutes for regular breaks and “x” minutes for immediate breaks. The guidelines can be configured such that, for instance, for every employee present during a shift, “b” employees can be assigned break time (this may vary based on the company’s policies and the nature of calls) because LLM-T-B adjusts capacity according to the volume of incoming calls. However, we will set a threshold to ensure that the number of breaks never decreases to zero.
Another rule is that if an employee is late returning from a break, they will receive the first warning after 1 minute and a second warning after 3 minutes. These warnings will be sent as notifications in the BOT. The company can decide how many warnings an employee can receive in a day and what actions to take in case of repeated delays. We will add a button called “Rest (dnd)” in the BOT. Pressing this button will display the message “Your break time is over,” and the employee will be notified of the current capacity.
If the capacity is full, the BOT will notify that the counter is over the limit and will not allow registration. The BOT can also be configured to announce the capacity in real time. An emergency capacity can be defined, as allowing each employee to use it once a day. A function ensures that if an employee uses this emergency capacity, they cannot use another emergency capacity until the end of their shift. Additionally, only one emergency capacity can be open at any time, with a 10-minute time limit.
During lunch and dinner breaks, different shifts can have varying break times. The break duration can be extended by “n+d” minutes during these periods. The scheduling system can set a 3-hour lunch period, during which each employee can take a break only once. If an employee exceeds this limit, a warning will be issued, and further break requests will be denied. If an employee takes too long of a break, error messages will be sent. Notifications for lunch/dinner breaks will be sent to available employees, not on calls. It will be emphasized that the designated break period will not be extended. After the designated break time, a message will be sent to all employees on the shift, and the new break capacity will be announced.
We will also create a reporting function to save a report of registered breaks in a database at the end of each shift.
The suggestions above are symbolic and can be adjusted by each company according to its conditions and internal policies. For very specific and urgent situations, administrative access can be granted for the BOT, allowing a human operator to modify settings in special cases. All the suggestions mentioned are completely flexible and can be easily changed based on the company’s decisions and policies. The purpose of mentioning these points is to emphasize how effectively and efficiently these potentials can be utilized. So far, we have defined basic and initial BOT rules. In the next section, we will implement this simple BOT using Telegram’s BotFather and Python code.
Implementing the Bot
In this stage, we need to create our Telegram Bot. Start by logging in to Telegram and searching for “BotFather”. Open the BotFather page and click the “Start” button. Once you do that, you will see instructions on the page. Choose the `/newbot` option. BotFather will prompt you to pick a Name and a Username for your Bot. The Name can be anything you want, but the Username must be unique and end with the word “bot”. We have chosen ‘ManagerBot’ as the Name and ‘CallCenterManagerBot’ as the Username. After creating the Bot, BotFather will provide you with an Access Token. This token is crucial as it is used to communicate with the Telegram API, so make sure to keep it in a safe place.
To implement the various rules mentioned earlier, we will use Python code. For this, I utilized `https://colab.research.google.com`. To connect to the Bot and use the Access Token, we need to install the `python-telegram-bot` library using the following command:
!pip install python-telegram-botOnce we have completed the initial steps of creating and registering the BOT, we proceed by searching for the BOT’s name in Telegram. Upon finding it, we can start the BOT by pressing the start button. Additionally, in BotFather, there is a user interface that allows us to configure the initial settings of the BOT. It’s also important to enable some access permissions in BotFather settings to make the necessary changes to the BOT.
Please note that the steps mentioned above and the code required to build it might be expanded in future versions of this article. It’s essential to highlight that these steps do not involve AI and can be easily implemented using Telegram. In the next section, we will be exploring the main topic: the core functionality of the BOT and the amazing tasks we will accomplish with LLM-T-B. Stick around as we further develop it.
Ask me!
One of the most important features we want this bot to have is a section called "Ask Me!" One of the main concerns for individuals working in a call center is to find answers to customer questions as quickly as possible. This is also important for other companies. Consider having a company that performs software tasks or a specific organization with certain administrative procedures, internal rules, and processes. This is especially relevant for companies that hire interns or newcomers who still need to become familiar with the standard procedures and complete regulations of the job. Therefore, "Ask Me!" can be useful everywhere.
Call center experts typically have access to a wide range of resources and documents that they can use to find answers during calls. Finding the best answer, especially for new experts, is always a major challenge in technical call centers. Relying solely on human resources or numerous documents scattered across various sections to answer questions leads to increased response times, longer call durations, and a decrease in the quality of the process.
"Ask me!" is highly beneficial, especially for customer interaction, such as when setting up a Telegram BOT (as an example in my capacity working for an ISP). This form of communication makes it easy for customers to inquire about modems and other ISP services. Instead of having to call and potentially wait in a queue, customers can simply engage in a conversation with the BOT to get answers. This allows for quick insights into modem types and various processes that would otherwise require direct contact and more time for both customers and sales staff. This approach can also be applied to sales, organizational services, or any other products a company offers. Potential customers, like those looking to purchase a modem, can obtain valuable information from the BOT with just a few questions. With this knowledge, they can then engage in more comfortable and informed interactions with sales representatives. The ultimate goal is for customers to feel as if they're conversing with a real person as "Ask me!" communicates in a natural language that closely resembles human speech, significantly enhancing the user experience.
Applications of LLM-T-B
Imagine if all the internal rules and processes of your company were as easy for AI language models (LLMs) to handle as a simple breakfast meal, especially for mid-sized or larger companies! After acquiring the LLM model, we can train it with the company’s data, documents, and tasks. All processes and rules can be easily tokenized and taught to the model. It can then be used for internal tasks and to answer questions from customers. For example, one of the most frequently asked questions in internet service providers (ISPs) that provide LTE internet is about coverage. Consider using LLM-T-B for the sales department, where one of the initial questions LLM-T-B asks is the location of potential modem buyers. It can easily check the coverage for them and provide the customer with information. More importantly, analyzing this valuable data can reveal areas with the highest and lowest demand for purchases, guiding more or less investment and targeted advertising in these regions.
Analyzing commonly asked customer questions provides us with incredibly valuable data. I'm not referring to the FAQs section on a website, but rather the numerous questions that arise in Call Centers. In using both frequently asked questions and those that agents typically struggle to answer, we can continuously enhance LLM-T-B. This allows us to ensure that when customers ask these questions, LLM-T-B can provide responses that are even more natural than those of humans. For instance, LLM-T-B can assist with tasks such as changing the modem's name and password, guiding a customer through the registration process on the customer panel, or providing advice on how to improve the security of a specific modem model. Even routine questions such as how to renew plans, change ownership, or resolve ticket-related issues can be addressed clearly and step-by-step by LLM-T-B, thus reducing the necessity for direct contact.
Remember this text: "These applications not only increase customer interaction and satisfaction, but they also significantly reduce the workload of various departments and enhance staff productivity. What is the most frequently asked question in your organization? Or in the call center, what is the most common question among new technical agents? Finding the answer to this question can provide valuable insights. It's worth mentioning that with Ask me! agents can get answers to necessary questions just by asking the bot, instead of searching for them manually. These are just a small part of the numerous applications of LLM-T-B* Today, we know that LLMs are becoming more powerful every day, enabling us to perform countless tasks with them."
Why LLM?
We can analyze the questions posed daily by agents or customers in the database designed for LLM-T-B. This analysis can greatly assist the company by identifying the most common problems faced by both customers and agents, as well as understanding the main reasons for customer inquiries. Additionally, it helps in pinpointing the areas where agents, especially new ones, need improvement in their responses. The stronger the agents, the faster the processes are completed. What is the solution? Undoubtedly, LLMs.
We don’t need a very large and powerful language model (LLM) because the documents within organizations are not extremely large. Once we use the LLM for some time, we will gather valuable information that can be used to retrain the LLM, making it more efficient and faster. This will increase the value of our LLM.
Which LLM?
There are various ways to utilize large language models (LLMs). One approach is to create a new model from the ground up. However, this task demands a significant amount of data and computational resources, which are typically only available to very large companies. Additionally, it’s not necessary to start from scratch, as there are alternative ways to leverage existing technologies.
For example, you can obtain an API from leading companies like ChatGPT or Anthropic, granting access to their LLMs. Another option is to utilize open-source models such as LLaMA 3, which offers a comprehensive architecture and access to a vast repository of information. However, even training a model like LLaMA 3 can be quite resource-intensive and expensive.
An alternative approach is to utilize smaller models. There are resources accessible, with one of the most prominent options in recent years being the Hugging Face platform. Almost all models can be accessed there. All that is required is an API from Hugging Face to utilize the pre-trained models provided on the platform.
Sure, here is the revised text: "What are the advantages? The most important benefit is increased security, as we can download these pre-trained models and use them locally on our systems. We only need to fine-tune and train them on the specific data to effectively respond to our BOT."
In the next section, we will learn how to implement, train, and connect our LLM to the Telegram BOT. Stay with me!
Note: The model we will use here is experimental, intended to demonstrate that this can be done. For main projects, we can use better and more secure models.
Implementation of LLM-T-B
After trying out different LLM models and utilizing various APIs, I ultimately opted for models offered by Hugging Face. However, I encountered challenges in finding a model that could meet our requirements without being too costly or computationally expensive. As a solution, I discovered a suitable model on GitHub and utilized it instead.
Our model, which is based on the GPT-4 architecture, is called “gpt4all-13b-snoozy-q4_0.gguf”.
To begin, I obtained the model by using the codes provided on GitHub in Google Colab. We now have the base model with its initial training. Our next step is to integrate it with our Telegram bot.
To begin, we'll need to acquire the API_KEY for our Telegram BOT from BotFather to establish communication between the Python code we're developing and our BOT. The documentation on GitHub indicates that we'll need two libraries to use this model, as detailed below.
# Import the telegram bot API
!pip install python-telegram-bot==13.7
!pip install gpt4all==2.0.2To utilize the BOT, we need to import various libraries that are essential for carrying out specific parts of the code. By studying these libraries, it becomes evident why and for which tasks we will be using them. I’ve added these libraries over time as different tasks were incorporated. Below, you can find some of them along with detailed explanations.
# Importing necessary classes and modules from telegram.ext for managing a Telegram bot
from telegram.ext import Updater, CommandHandler, MessageHandler, Filters, CallbackQueryHandler
# Importing necessary classes and modules from telegram for managing inline buttons and keyboard
from telegram import InlineKeyboardButton, InlineKeyboardMarkup, ReplyKeyboardMarkup, KeyboardButton
# Importing GPT4All library to use the GPT-4 language model
from gpt4all import GPT4All
# Importing threading module for running concurrent threads
import threading
# Importing googletrans library for translating text
from googletrans import Translator
# Importing langid library for detecting language of the text
import langid
# Importing logging module to log messages and events
import logging
# Importing sqlite3 module to interact with SQLite databases
import sqlite3
# Importing os module for interacting with the operating system
import os
# Importing queue module to create and manage queues
import queueWhen developing your code, remember to include the Telegram API_KEY token. To proceed with using the BOT, we first need to import and initialize the model.
# Telegram bot token (replace with your bot token obtained from BotFather)
TOKEN = 'YOUR_BOT_TOKEN'
# Select LLM model from gpt4all
model = GPT4All("gpt4all-13b-snoozy-q4_0.gguf")We will use the following code to connect to the Telegram BOT and download the desired LLM model to our system, making it readily available. Next, we will add tasks to our LLM-T-B. The initial task I worked on was enabling the BOT to be capable of translating into the user’s language. For instance, our model is proficient in English and understands Persian but cannot respond in Persian. We have two approaches: the first is to train the model with a dataset containing Persian sentences and their translations into English. This method is challenging as it requires resources such as powerful hardware with strong GPUs or GPU servers available in the cloud, which can be costly. The second approach involves using the `googletrans` library and its `Translator` class. We need to install this library first.
!pip install googletrans==4.0.0-rc1With the code snippet I will provide, we can create a rule for LLM-T-B. When a user writes in English, the responses will be in English, and when the user types in Persian, they will receive a Persian response. However, this approach may have some drawbacks, as it requires additional computation to translate the user input into English and then translate the English response into Persian.
# Translator instance
translator = Translator()
....
# Detect language of user message
lang, _ = langid.classify(user_message)
# Translate user message to English if needed
if lang == 'fa':
translated_prompt = translator.translate(user_message, src='fa', dest='en').text
else:
translated_prompt = user_message
# Add the prompt to the user's queue
user_queues[chat_id].put(translated_prompt)The model generates responses in English, which can be translated into Persian using the provided code.
# Translate the response back to the user's language if needed
response = user_contexts[chat_id]['response']
if lang == 'fa':
translated_response = translator.translate(response, src='en', dest='fa').text
else:
translated_response = responseDatabase
The next important step is to set up a database for the bot. There are several options available for this. We can use free or subscription-based databases. Free or low-cost databases like SQLite or PostgreSQL are good options. When using SQLite, the data is stored as a physical file on disk and will not be lost when the program is closed. However, if we want the database to be online and always accessible, we can use online storage services like Google Drive.
For using Google Drive as an online database, we can use Google Sheets as our database. The Google Sheets API can be easily used with Python. In the following section, we will see the steps for setting up an SQLite database and integrating it with the Telegram bot. SQLite is a lightweight, embedded database that does not require a server by default, making it suitable for small to medium-sized projects. In the code snippet below, which is part of the main LLM-T-B code, we will learn how to create a simple database.
# Function to delete and recreate the database
def initialize_database():
# Check if the database file exists and remove it
if os.path.exists('bot_database.db'):
os.remove('bot_database.db')
# Connect to SQLite database (it will create the file if it doesn't exist)
conn = sqlite3.connect('bot_database.db')
cursor = conn.cursor()
# Create the users table with columns for id, user_id, and first_name
cursor.execute('''
CREATE TABLE users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id INTEGER UNIQUE,
first_name TEXT
)
''')
# Create the questions table with columns for id, user_id, question, and answer
# user_id column is a foreign key that references the user_id in the users table
cursor.execute('''
CREATE TABLE questions (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id INTEGER,
question TEXT,
answer TEXT,
FOREIGN KEY (user_id) REFERENCES users (user_id)
)
''')
# Commit the changes and close the connection
conn.commit()
conn.close()
# Initialize the database by calling the function
initialize_database()
# Connect to SQLite database (check_same_thread=False allows for multithreading)
conn = sqlite3.connect('bot_database.db', check_same_thread=False)
cursor = conn.cursor()Buttons
The next step involves creating buttons for the BOT, which is optional. It is easy to integrate any button into the BOT to symbolically showcase the functionality of LLM-T-B. I plan to add three buttons to this bot: Start, Ask me!, and Help. In the code, I will specify the messages that should be displayed when the user presses each of these buttons. This task can even be delegated to the LLM.
When the user presses the Start button, they will be greeted with the message: “Hello (user’s username), welcome to the Ask me! BOT. If you have any questions, I would be happy to help. Just press the Ask me! button and ask your question.” After pressing the Ask me! button, the bot will tell the user, “(user’s username), please ask your question so I can quickly respond.” Then, LLM-T-B will take the user’s questions and provide answers.
In addition, beneath each response that the BOT provides to the user, we will include an exit button. When this button is pressed, the user will receive a polite message thanking them for using the BOT and expressing eagerness to help them again. I will stick to three buttons for now, as I believe that a simpler and less cluttered user interface is more appropriate to avoid user confusion. I think the power and appeal of simplicity to attract more users can often surpass many elaborate features.
It is important to note that when creating buttons for your LLM-T-B, simply creating buttons and displaying messages to the user is not enough. For instance, the Start button was defined and present but did not function, or in another example, the exit button that I defined in the BOT displayed a message when pressed but did not perform any action. It took several attempts, including error checking, running, and restarting, to understand and fix these issues.
start the LLM-T-B
We need to test the BOT. I have tested it several times and encountered issues when testing it with different users. One problem is that when two users enter the BOT simultaneously, the BOT mistakenly thinks they are in the same environment. It doesn’t distinguish between users. For instance, if I ask a question and another person also enters the BOT and presses “Ask me!”, the BOT would display the response meant for the first user to the second user as well. To address this issue, we need to implement a queue mechanism for requests so that each user has a separate queue for their requests and responses. Additionally, we should use threading and Queue to manage these queues.
# Store the contexts and queues for each user
user_contexts = {}
user_queues = {}In this code, a queue and an event are created for each user to manage messages and responses separately. This approach helps segregate messages for each user, ensuring that they receive relevant responses to their queries. The sections of the code responsible for this are explained below: When a new message is received from a user, if the queue and event corresponding to that user don’t exist, they are created.
# Wait for response event to be set by conversation thread
user_contexts[chat_id]['response_event'].wait()
user_contexts[chat_id]['response_event'].clear()The code snippet below is intended to handle concurrent and separate conversations with multiple users. In this code, each user has a dedicated conversation loop that takes messages from the user’s queue, sends them to the LLM model for processing, generates a response, and then stores the response in the user’s context. A response event is triggered afterward. If the queue is empty and the conversation has ended, the loop will stop.
# Function to start the conversation loop
def startConversation(chat_id):
global user_contexts, user_queues
with model.chat_session():
while True:
try:
prompt = user_queues[chat_id].get(timeout=5)
print(f"Working on prompt for user {chat_id}")
# Generate response
response = generateResponse(prompt)
user_contexts[chat_id]['response'] = response
print(f"Finished processing for user {chat_id}")
user_contexts[chat_id]['response_event'].set()
except queue.Empty:
if chat_id not in user_contexts or not user_contexts[chat_id].get('is_running', False):
break
print(f"Exited conversation loop for user {chat_id}")
The function `startConversation` begins a conversation loop for a specific user identified by the `chat_id`. It uses global variables `user_contexts` and `user_queues` to manage user contexts and message queues. The `with model.chat_session()` ensures that a chat session is established and maintained with a large language model (LLM) throughout the conversation loop.
Within the `while True` loop, it tries to retrieve a message (`prompt`) from the user’s queue (`user_queues[chat_id].get(timeout=5)`). If the queue is empty, it waits up to 5 seconds for a new message. If no message arrives within this timeout, it raises a `queue.Empty` exception, which is handled by the `try-except` block.
If the queue remains empty and the user’s conversation is no longer active, the conversation loop ends. This design ensures that user messages are processed separately and concurrently, without continuously consuming system resources.
Testing LLM-T-B
After writing the LLM-T-B code, the next step is to execute it to see it in action on the Telegram bot environment. I tested the code on Google Colab for better performance and stable connectivity, but it is preferable to run it on a server, preferably a Linux server. After running the code and downloading the model on Colab, the code is executed line by line. Following the code execution, the bot should be started in the Telegram environment. I have two Telegram accounts named “Javad” with a capital “J” and “javad” with a lowercase “j” for testing purposes. Both Telegram accounts are on the same device and only differ in the capitalization of the username. I initiated the LLM-T-B start command, and in both environments and with different usernames, LLM-T-B easily provided correct answers to the questions posed. You can refer to the image below.
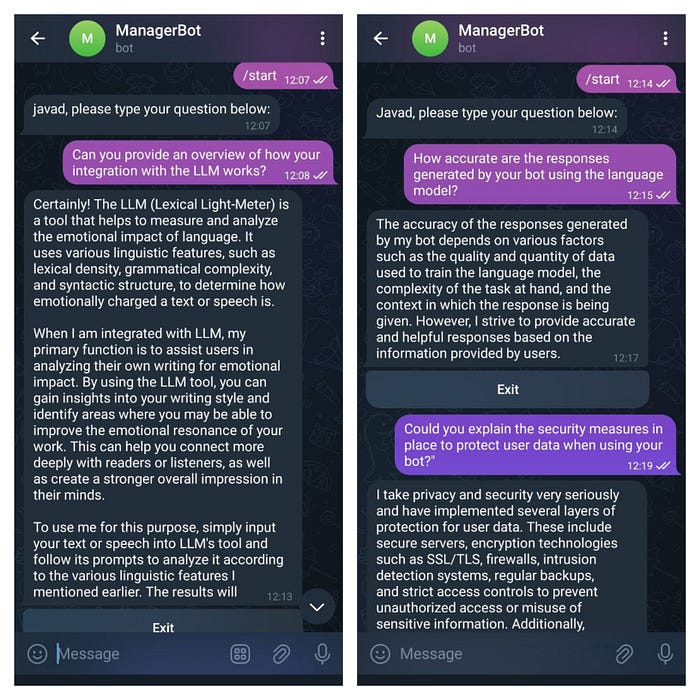
In the image, you can see the bot starting by asking the user a question. The user then asks their question, and the bot connects to it using LLM to provide an answer. Below, you can see that each user has a unique ID assigned to distinguish them for LLM-T-B to recognize and easily categorize in the database. We have seen the implementation code and details of this task above.
Received message from user: How accurate are the responses generated by your bot using the language model?
Working on prompt for user 6514170446
Finished processing for user 6514170446
Received message from user: What languages are supported for translation using your bot?"
Working on prompt for user 1932960851
Finished processing for user 1932960851
Received message from user: Could you explain the security measures in place to protect user data when using your bot?"
Working on prompt for user 6514170446
Finished processing for user 6514170446
Received message from user: What types of tasks or queries do you handle best?"
Working on prompt for user 1932960851
Finished processing for user 1932960851In the text below, there are two IDs, 1932960851 and 6514170446, which belong to two different users. For testing LLM-T-B to see if the model works well even without training and just with the translated code, I conducted some Q&A in Persian, as shown in the image below.
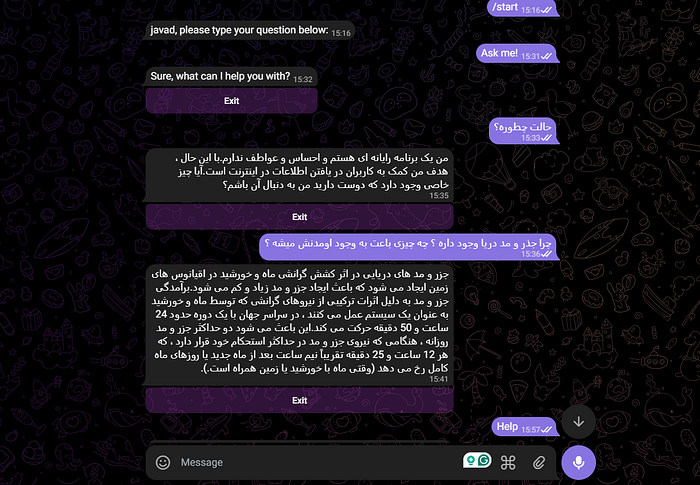
It’s important to address any issues that may arise during the development of the model and the bot. One common problem with LLMs is “hallucination,” and we must work to minimize this issue. An example of this can be seen in the image below. It’s worth noting that the model used in this article has not undergone additional training and is not connected to the Internet.

When running bot code in Google Colab, you might encounter significant issues such as crashing and session resetting. This is due to the less efficient performance of Google Colab compared to running code on Linux or a powerful server. If you face this problem, simply rerun the code. Furthermore, each time you reset or change the session in Colab, you will need to reinstall the libraries.
Security of LLM-T-B
It is crucial to consider the security of the BOT, especially when it is publicly accessible and used for sensitive purposes like customer communication or sales. The initial issue to address is the underlying LLM. The models mentioned in this article, including pre-trained and open-source models, are downloaded and deployed locally for customization. Consequently, the model itself can be highly secure.
The next concern involves the users who interact with the chatbot and may try to launch attacks. Use models from trusted and secure sources. While open-source models can be secure, make sure to download them from reputable sources. Keep models and related software regularly updated to take advantage of the latest features and security fixes.
Please restrict access to the BOT so that only authorized users can use it. This can be achieved through whitelists or two-factor authentication. For example, technical support for modems should only be accessible to individuals with registered modems whose information is in the company’s database. Alternatively, a verification process should be performed where user information is collected before accessing the model. If users have any questions regarding the purchase of a modem, their messages should not be directly connected to the LLM model. Instead, their queries should be received in a BOT environment that does not permit access to the LLM. The user’s query should be received in the database and sent separately for processing to the LLM, and the generated response should be returned to the database and sent back to the BOT environment.
To ensure the security of the BOT server, all communications should be conducted via HTTPS to encrypt data during transmission. Using DDoS protection services can help make the BOT resistant to sudden and heavy attacks.
It’s important to log all activities and requests and continuously monitor them to quickly identify and stop any suspicious activity. Inputs should be validated to prevent malicious data entry, which includes using input filters to prevent SQL injection and XSS attacks.
To maintain privacy, securely store user data and prevent unauthorized access. This includes encrypting sensitive data and restricting access rights. Educate users about security and potential risks so they can play their part in maintaining security.
Conclusion
In this article, an attempt was made to introduce an idea that is currently gaining attention in the AI world. The points discussed in this article touch on only small aspects of LLM applications. Yann LeCun advises those learning AI or starting, “DO NOT WORK ON LLMs,” suggesting that creating LLMs from scratch and working directly on building them may not be very reasonable. However, using them for various applications, and tasks, and developing new products with LLMs can be very beneficial. The approach followed in this article focuses more on having a very simple user interface to assist customer relations experts. This speeds up tasks, improving response quality and increasing customer satisfaction quickly, a matter explored thoroughly in the introductory sections of the article.
Many tasks can be added to LLM-T-B briefly:
1. Online Chat Tasks: online chat is a vital communication tool for businesses, big and small. Many major companies use it on their websites. One major challenge faced in online chat is the delay in response times, which has been improved with LLMs. However, we can focus on using past chat data with customers to train the model to provide real-time, natural language responses, so customers do not feel they are chatting with AI. Additionally, utilizing sentiment analysis tasks, at which LLMs excel, can be very valuable. Analyzing this information can greatly help us provide better customer service and pay more attention to the company’s strengths and weaknesses. I have extensive experience in online chat and am very familiar with it. This approach can significantly increase the speed and 24-hour support coverage, reduce human error, and improve customer satisfaction more than ever.”
2. Ticketing Tasks: I have encountered this issue many times, and it can sometimes lead to customer dissatisfaction because it is time-consuming. LLM-T-B can be developed in a way that allows customers to easily find comprehensive solutions to their problems, and even get the confirmation they need instantly or in a short amount of time if they need to use an identification card. By automating more processes and improving speed and quality through high model accuracy, customer satisfaction can be further improved.
3. Potential Customer Tasks: Those who have not yet taken steps to purchase or use the company’s products, but intend to do so, can be directed to the sales department. The department can gather initial information from these individuals for product presentation, or follow up with them to persuade them to make a purchase. Restructuring the sales department has proven to be very effective and has even facilitated increased use. We are very pleased with the results!”
In conclusion, it can be said that this idea has potential for use in various other contexts, producing positive results. Thank you for reading this article and sticking with me until the end. I would love to hear your thoughts on this piece. Thank you!
Thank you for accompanying me on this journey into the world of deep learning.
The link to the article in Persian is available on virgool.io.
If you’re interested, you can check out my other article, “Transformers: AI’s Paintbrush to Paint a New World (Vision Transformer)”
Decoding Commonalities: Finding the Longest Common Prefix in Strings (Python Code)
I hope you’ve enjoyed the content.

